Your agents break? You know first. Not your users.
A dashboard of every agent you have in production. Green means healthy. When something drifts — accuracy drops, costs spike, safety degrades — you get an alert with what happened and what to do about it.
What your team gets.
Every agent scored on production traffic. Same dimensions you defined in training — no gap between what you tested and what runs.
Accuracy drops from 0.78 to 0.61? You get a Slack alert in minutes. Not a support ticket next week.
Every dollar tracked by surface — agent calls, eval runs, training cycles, certification checks. No surprise bills at month end.
When quality drops below your threshold, retraining starts on its own. The agent adapts without your team scrambling.
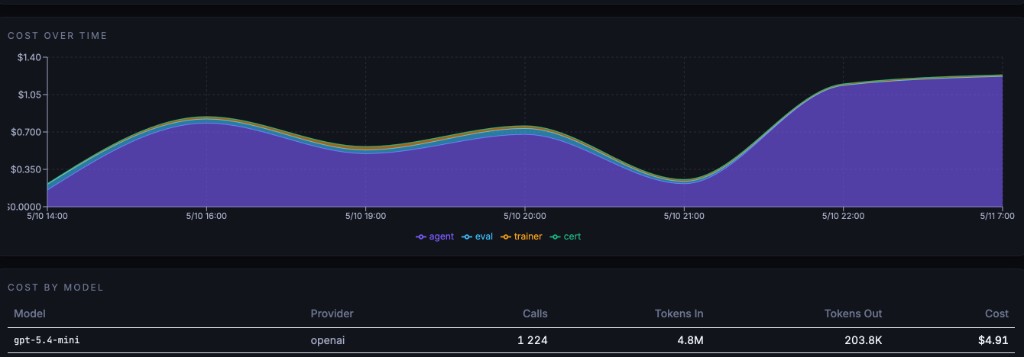
Fleet-level view — all your agents, one screen.
When one agent degrades, it often means something changed upstream — a model update, a data source issue. You see the pattern across all agents, not just one.
Business outcomes.
Show stakeholders that agent quality meets targets — with live data, not quarterly reviews.
Transparent per-run and per-cycle costs (example: $4.91/cycle with gpt-5.4-mini) — every cost visible and allocated. No more estimation games.
Continuous scoring and alerting creates a live audit trail. When regulators ask "how do you know your agents work?", you have the data.