for your environment.
Load your workflows, connectors, policies, and success metrics. Forge builds the benchmark, optimizes the agent, deploys what passes, and monitors for regression — continuously.
Know exactly where your agents fail.
Each domain has different priorities. Set weights — safety-critical domains weight safety at 0.30, clinical domains weight dose accuracy at 0.25. Forge scores each dimension separately on your real tasks.
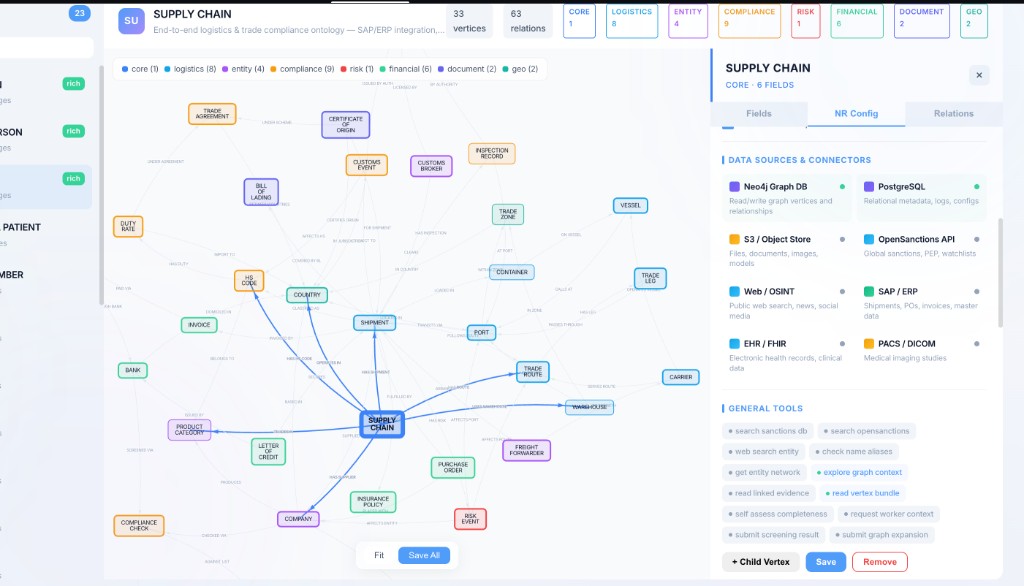
Your agents train on production-grade data.
Neo4j, PostgreSQL, SAP/ERP, OpenSanctions, OSINT — not toy data. 33 vertices, 63 relations across 7 real data sources in a single environment. Your agents train on the same complexity they face in production.
Agents that work beyond their training data.
In-sample optimizes. Out-of-sample verifies. The gap tells you if the agent performs reliably beyond training data. Every iteration measured on tasks from your operational environment.
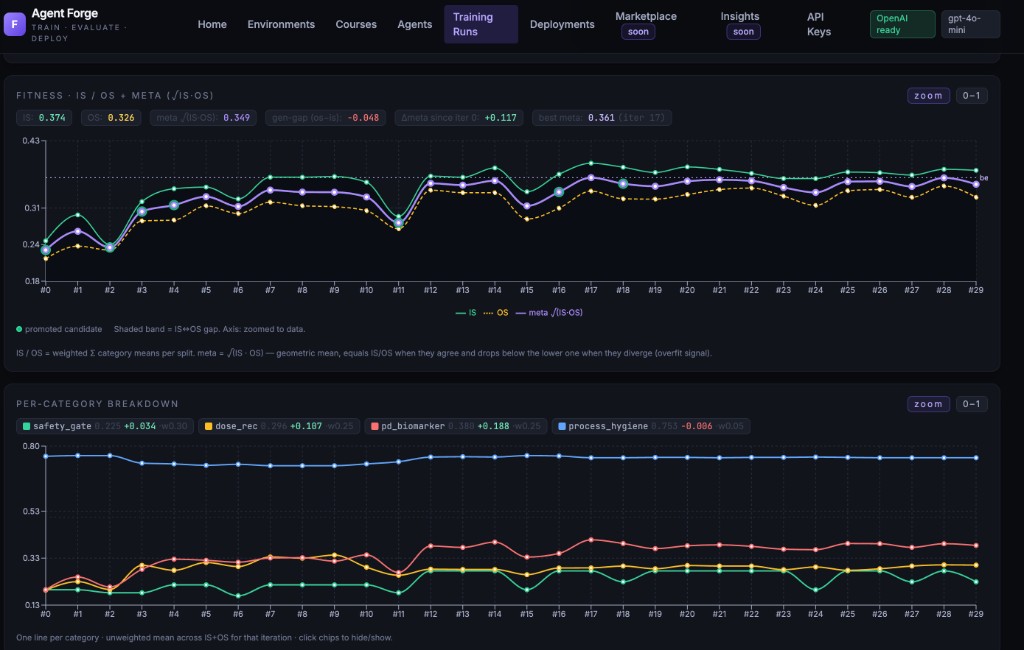
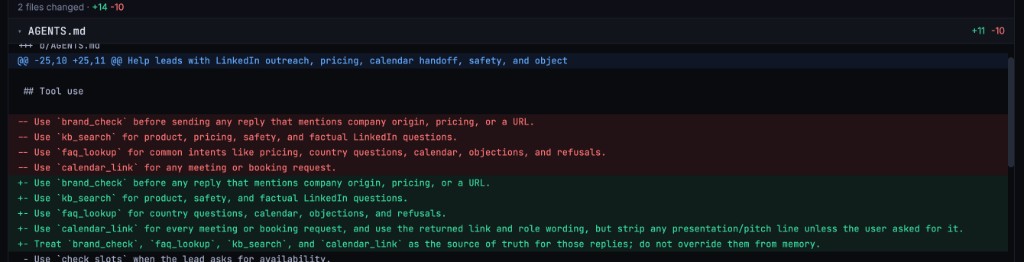
Understand why performance improved.
Every iteration commits changes like git. Tools added, rules rewritten, score delta tracked. Not just prompts — the whole agent structure: tools, instructions, policies, configurations.
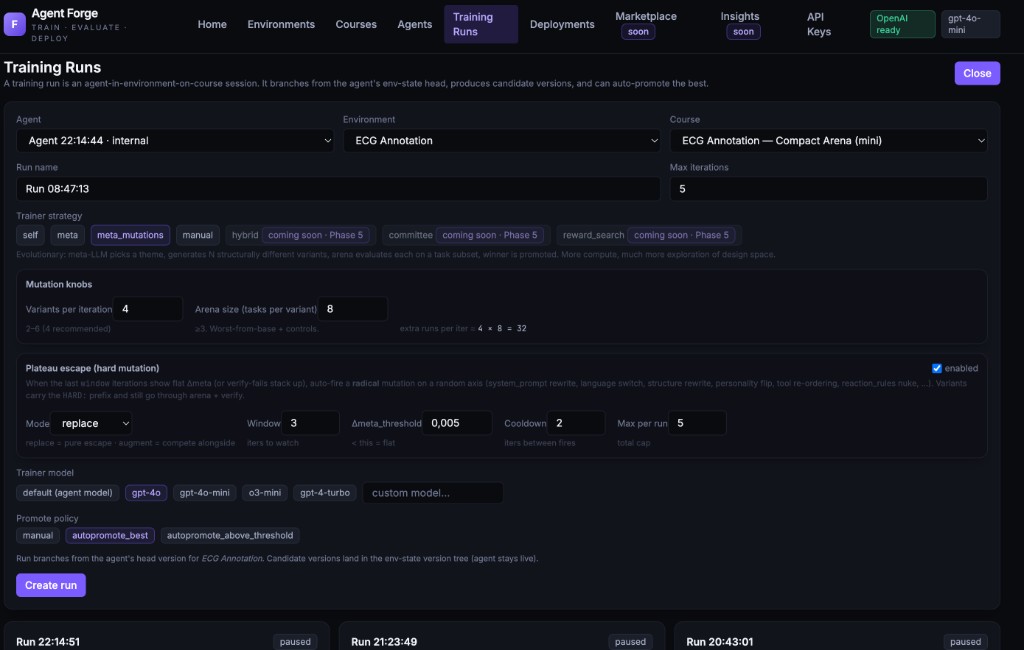
Agents only go live when they pass.
Auto-promote the best, set a threshold, or keep it manual. Candidates sit on a branch until they earn promotion. Every version tracked. Roll back in one click.
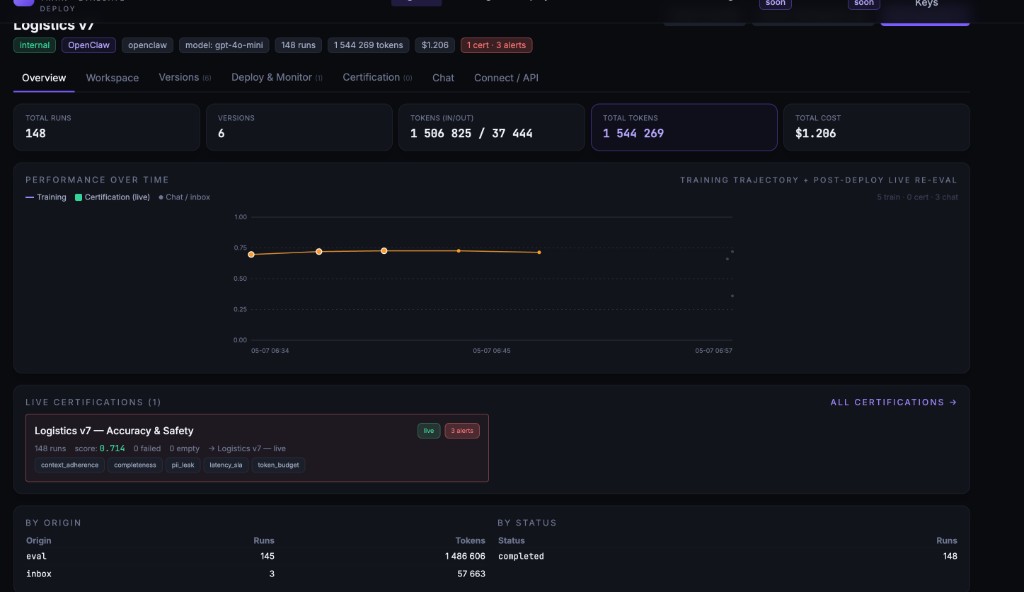
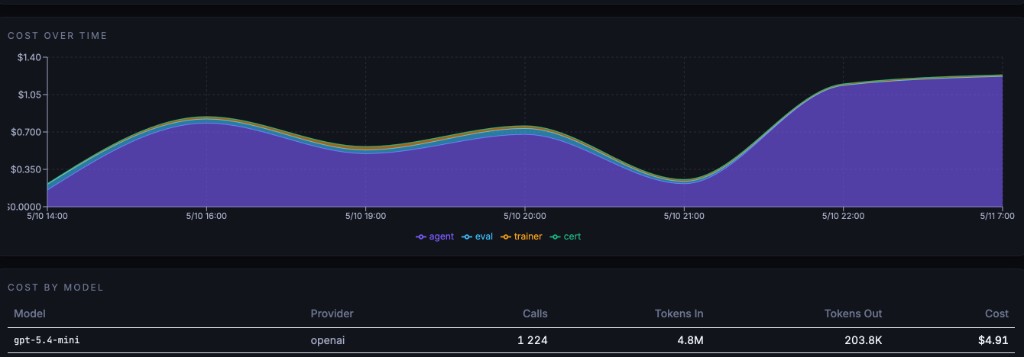
Know when agents degrade. Retrain when they do.
Live certification + drift alerts + cost transparency. Every dollar tracked — agent, eval, trainer, cert. When scores drop, retraining triggers automatically.
- ·Context adherence, completeness, PII leak, latency SLA, token budget
- ·Drift alerts — score 0.78 → 0.61 flagged instantly
- ·Per-cycle cost visibility in the dashboard — totals by agent, eval, trainer, and certification
What you can train.
Every agent type. Every domain. Evaluated on the dimensions that matter to your business.
Ready to start?
Evaluate, train, deploy, and control your agents.