Fix what's broken. Automatically.
In-sample trains. Out-of-sample proves. The gap between them tells you if the agent generalizes. Every iteration is measured on tasks from your environment — not synthetic benchmarks.
Agents that work beyond their training data.
Three curves show the full picture: in-sample fitness, out-of-sample fitness, and the meta score. When the gap between them shrinks, your agent is learning to handle tasks it was never trained on.
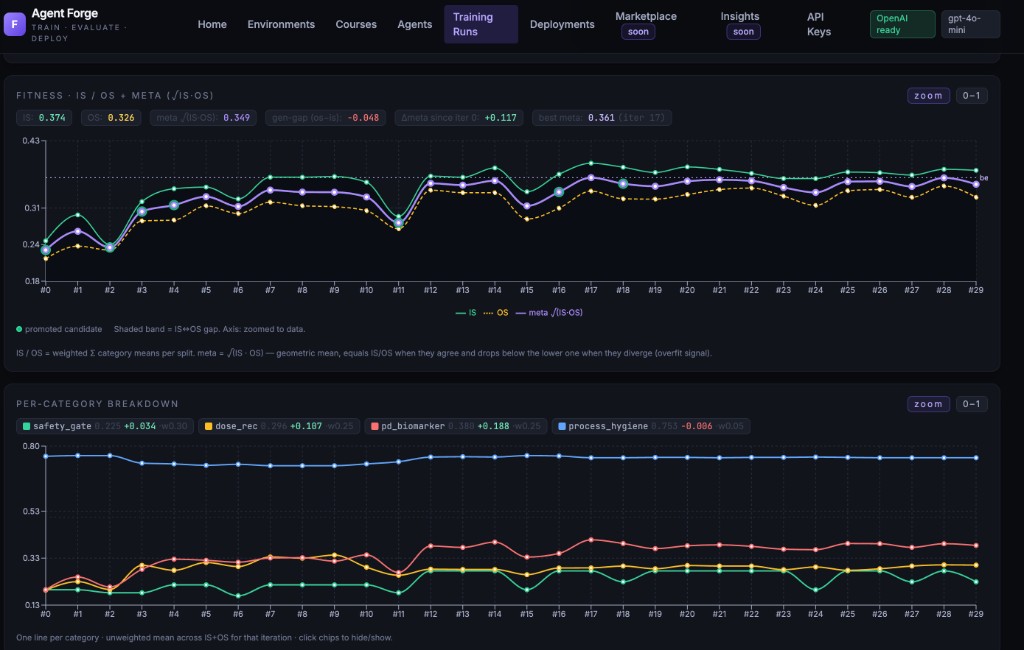
Understand why performance improved.
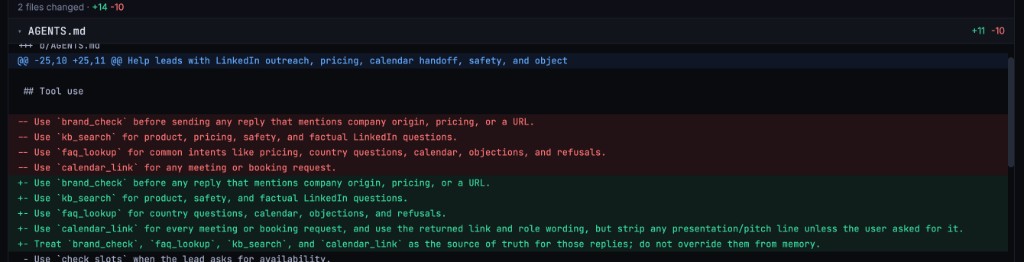
Every iteration commits changes like git. Tools added, rules rewritten, score delta tracked. Not just prompts — the whole agent structure is visible: configurations, policies, and tool definitions.
You choose how much control to keep.
From fully manual review to autonomous evolution — choose how much control you keep at each stage.
Full control. You review traces, you edit config, you decide what ships.
The agent analyzes its own mistakes and proposes fixes. You approve or auto-promote.
Generate config variants. Arena picks winners. Pareto-optimal selection across objectives.
Edits the full agent as files — prompts, tools, rules, code. Git-native workspace.
Focuses on one evaluator at a time. Improves iteratively until plateau, then moves to the next.
Agents fix more on their own as you gain confidence.
Each depth level adds a deeper kind of change the system can make. Start with prompt adjustments, progress to full tool creation. The deeper the level, the more the agent can fix on its own.
How a training cycle looks in practice.
A logistics agent scores 0.31 on iteration 1. Here's what the trainer changes at each depth level to reach 0.73 by iteration 23.
Iteration 2: Trainer rewrites the system prompt to emphasize checking sanctions databases before approving any shipment. Score: 0.31 → 0.38.
Iteration 6: Trainer adds "always_query" flag to the sanctions_check tool, ensuring it runs on every entity. Score: 0.38 → 0.49.
Iteration 11: Trainer adds a rule: "if HS code is dual-use, escalate to compliance review before proceeding." Score: 0.49 → 0.58.
Iteration 16: Trainer creates a new tool verify_entity_chain that cross-references beneficial owners across three registries. Score: 0.58 → 0.68.
Iteration 23: All improvements compound. The agent now handles sanctions screening, dual-use goods, and entity verification in one pass. Final score: 0.73.
Ready to see training in action?
Iterative training on your tasks and your data.