enterprise agents.
Your workflows, your tools, your KPIs. One platform that evaluates, optimizes, deploys, and controls agent systems in your operational environment.
You see exactly where agents fail — and which failures matter most.
40+ composable evaluators — statistical checks, rule-based validation, LLM judges. Chain them in any order, weight each dimension for your domain. Every score normalized to [0, 1].
Agents that stop failing on your specific tasks.
In-sample and out-of-sample fitness tracked separately to confirm real improvement — not memorization. Five training strategies, from prompt tuning to full tool creation. When agents degrade, retraining starts automatically.
Nothing reaches production unless it earns its way there.
Candidates sit on a branch until they pass your criteria. Auto-promote the best, set a threshold gate, or require manual review. Every version tracked, every decision reversible.
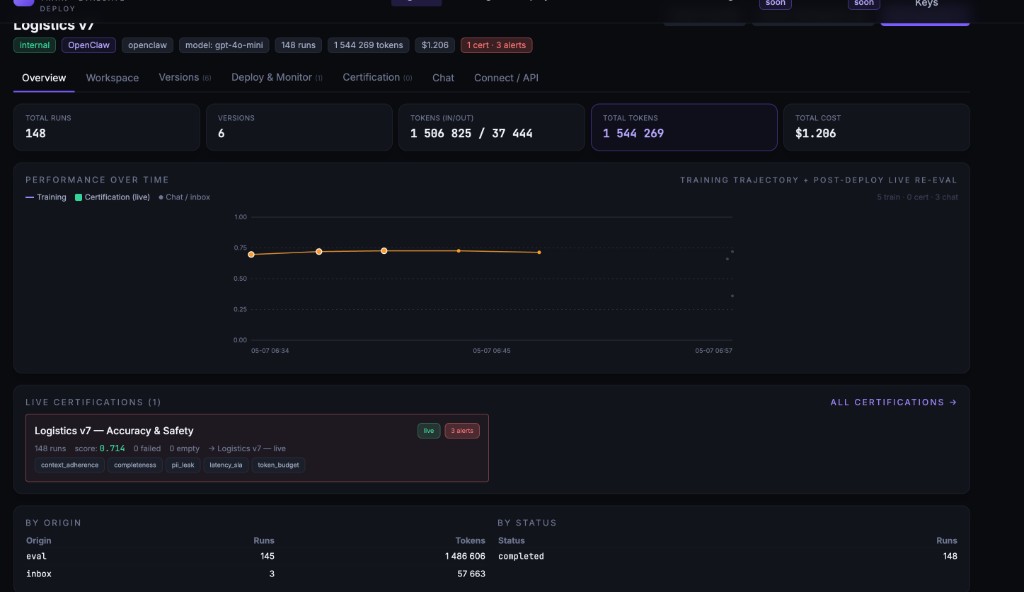
You catch degradation before your users feel it.
Continuous scoring of production traffic. Drift alerts flag quality drops early. Cost tracked per dollar — agent, eval, trainer, cert. When scores fall, retraining triggers automatically.
Agents improve at every level — not just prompts.
Each depth level unlocks more of the agent for optimization. L0–L3 are in production. At L3, trainers create new tools autonomously.
Explore the platform.
Know where agents fail. What to fix. Whether fixes worked. Composable eval chains with 40+ evaluators.
Agents stop failing on your specific tasks. 5 strategies, depth levels L0–L3, automatic re-optimization.
Only what passes goes live. Version control. Gated promotion. Rollback.
Drift detection. Cost tracking. Fleet-level monitoring. Auto-retrain on degradation.
Graph-native environments. 33+ vertex types. Real data complexity.
L0–L4 depth ladder. Where Xplore fits in the stack.
Self-serve. Pay as you go + early access credits. API keys, SDKs.
On-prem. SLA. Audit trail. Custom integrations.
API reference. Integration guides. Getting started.