production AI agents.
Your workflows. Your data. Your success metrics. One platform for the full agent lifecycle — from first scorecard to production confidence.
Know exactly where your agents fail.
Build a benchmark that simulates your agent's real work — then score it with composable evaluators. Safety, accuracy, tool usage, process compliance, cost, reasoning — 8 evaluator types, each weighted for your domain.
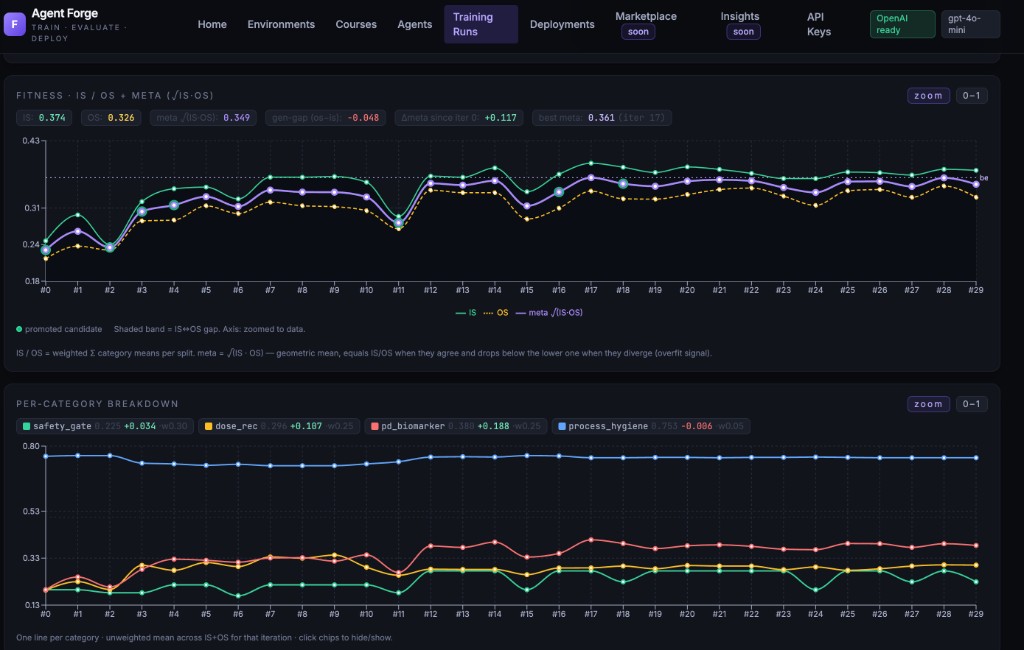
Fix what's broken. Automatically.
Forge optimizes your agent against the scores that matter to you. Every iteration is measured on tasks from your environment — not generic benchmarks. Every change tracked: tools added, rules rewritten, prompts adjusted.
- ·Automated cycles, tested on out-of-sample tasks from your environment
- ·Full diff between versions — see what changed and why scores moved
- ·Scores drop → retraining starts on its own
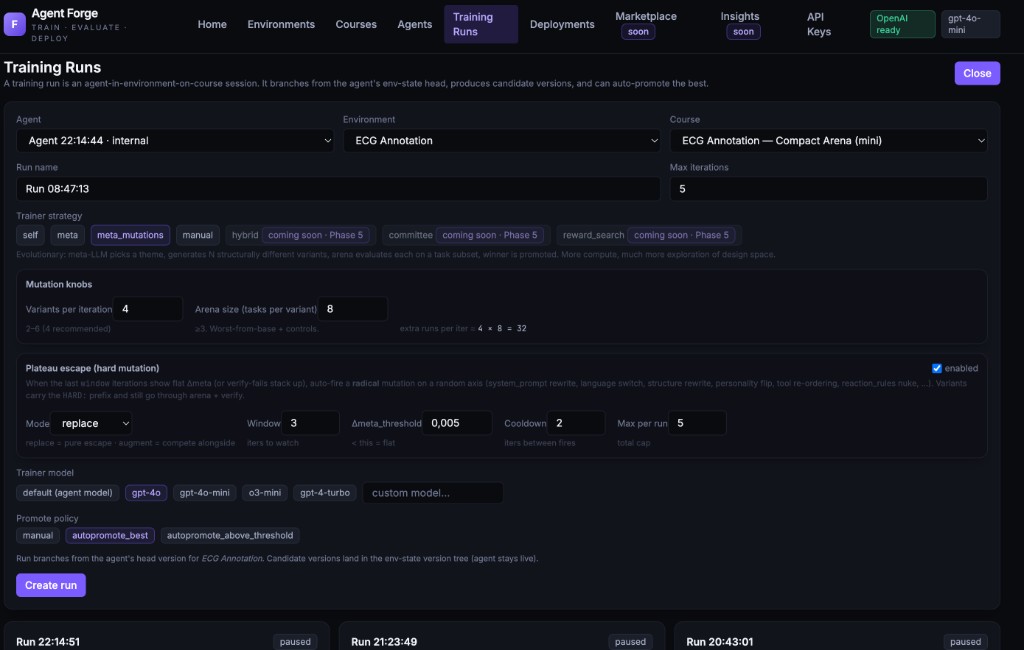
Agents go live when they're ready. Not before.
Four gates between training and production. Set a score threshold, let the best candidate win, or review manually. Every version tracked, every promotion reversible.
- ·Best performer goes live automatically — or you approve
- ·Score threshold gates — nothing below your bar ships
- ·One-click rollback to any previous version
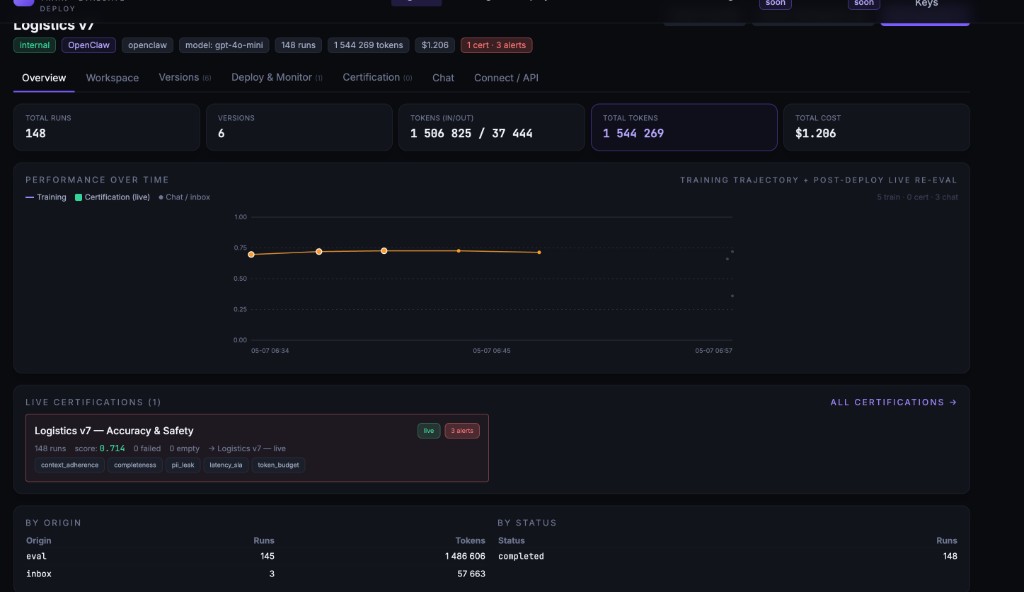
You know before your users do.
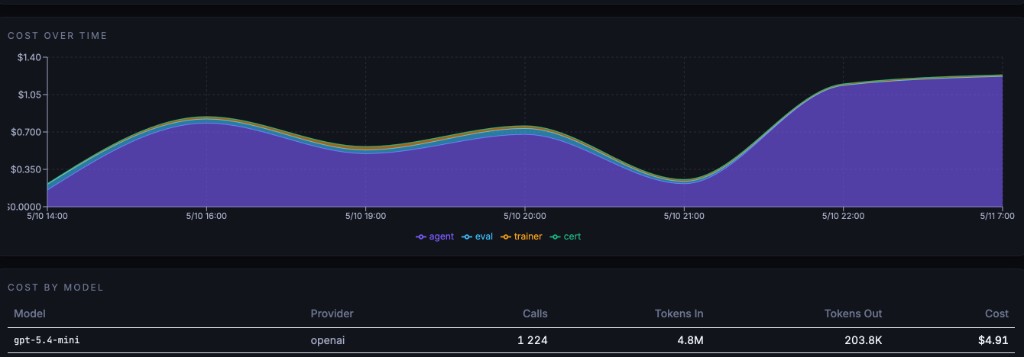
Every agent scored live in production. Drift detected the moment quality drops. Cost tracked per dollar — agent, eval, trainer, certification. When something breaks, retraining triggers automatically.
- ·Safety, accuracy, cost, latency — every dimension scored live
- ·Score drops from 0.78 to 0.61 → alert fires instantly
- ·from $4.91 per cycle (example run, gpt-5.4-mini) — every dollar visible
Forge + Agent 007
Forge runs the full lifecycle on your data. Agent 007 proves agent quality on public industry benchmarks.
Connect your workflows, tools, and KPIs. Forge scores every dimension, optimizes what's weak, and keeps agents reliable in production.
Logistics, trade compliance, clinical research, IT ops — simulations built from real business processes. Public leaderboards and competitions.